free for commercial (and every other) use
2020-10-29

In an attempt to fund the development of Eunice, I kept it free for open source, education and training, but after an evaluation period, I asked for a subscription fee for commercial use. This is no longer the case, Eunice can now be used for any purpose for free. There is no longer a custom license that needs accepting when running the software.
The main reasons for making this change are two fold. The available analyzers, for JavaScript and C#, are averaging 38 and 25 downloads per day respectively. So it would appear that they are being used; however traffic to this website is low and subscriptions are non-existent. This means having Eunice as my primary focus isn't currently sustainable due to the lack of funding. It may also be the case that having an end-user license with commercial restrictions is limiting potential to build momentum in awareness.
Eunice analyzer packages now specify a standard Creative Commons Attribution No Derivatives license. This license matches that, although they are now completely free to use, they're also not currently open source. If there was interest in other people contributing to the current analyzers or a creating new analyzers for other languages I'd consider making Eunice open source if it help the ideas behind it spread.
I will continue to work on Eunice, but only as a side project in my free time. I still believe using it would benefit most developers. Even if usage remains low, it is a good way for me to develop the broader ideas behind it and improve my breadth of understanding in different programming languages, by potentially writing analyzers for them.
shelving the multi-language analyzer written in Rust
2020-09-30
Although I was making progress, I've decided to shelve the development of the multi-language analyzer I was writing in Rust. The decision wasn't based on the technology choices made (e.g. using Rust), but rather on how productive I believe creating a multi-language analyzer will be.
Libraries to analyze the syntax or semantics of a language are often only available to software written in that language, or those that share a runtime. So a new multi-language analyzer was being developed that would be limited to file/module/namespace imports. Basic parsing and regular expressions would be enough to implement this functionality.
As Rust was being used to implement the multi-language analyzer, the first language it would analyze was also Rust. However, I was finding that, even while limiting the analysis to file imports, which are syntactically unambiguous in Rust, it was taking a long time to implement.
After further research, I also realized that unlike Rust and other languages, comprehensive support for namespaces might be impractical. Based on my experience of C# code, support for packages in Java would miss dependencies, as this is possible without specifying an import.
While looking at Rust libraries that might be helpful and examples of what would be required to analyze other languages, it seemed for a lot of codebases, analysis of just file/namespace imports wouldn't be detailed enough. There was often structure only as multiple packages or services and then as code files, with little structure in between.
I think comprehensive support for fewer languages would be more useful. Doing so could include the ability to see inferred stacks for the contents of files. Supporting features like this would require syntax parsing or a semantic model, and thus require the creation of individual analyzers for each language.
how cohesion and coupling relates to Eunice
2020-09-18
In some feedback on Eunice's website it was highlighted how there wasn't an explanation of why it encourages dependencies to be made unidirectional. While developing the ideas behind Eunice and then using it, the benefits have been demonstrated to me. However, this isn't going to be the case for people first visiting the site as potential new users of Eunice.
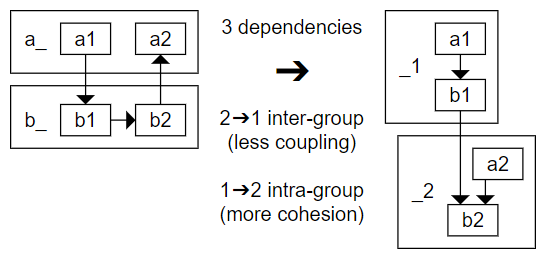
This feedback made me consider what characteristics Eunice was encouraging in software. I realized that cohesion and coupling weren't being mentioned in relation to Eunice. For people with experience in making software these terms are well known and have clear connotations, cohesion good and coupling bad. In practice, when applying these concepts, this can seem like a simplistic way to think about them. Although separate, they can be competing and effort to improve one can be to the detriment of the other. There's a lot of great explanations and diagrams out there to help people realize these two concepts; however, in application they're open to an individuals perception.
Tools that analyse, measure and visualize software structure and dependencies can incorporate cohesion and coupling, and so can help to coordinate their consistent application. There are many tools available that take different approaches to visualizing your software into interactive diagrams, Eunice being only one of them. However, I think Eunice's opinionated, yet non-prescriptive approach regarding the benefits of unidirectional dependencies has a distinct influence on efforts to improve cohesion and coupling.
This posts image is a generalized diagram showing an example of how Eunice's approach relates to the concepts. I've updated the home page and how it works pages with some references to cohesion and coupling, and the diagram.
writing an analyzer in Rust and a recently introduced bug
2020-09-07
Work on what will eventually be a multi-language analyzer is progressing in Rust. I think I've got my head round most of the common ownership scenarios I'll use in Rust e.g. first-class function arguments, iterators.
I've been thinking that there are at least two categories of module analysis that will need supporting. The first is for languages that either wholly or mainly base their module system on file-system paths. The second is for languages that use namespaces and that don't use file-system paths. From my use of Rust so far, it fits into the first category, so this is what I'm implementing first.
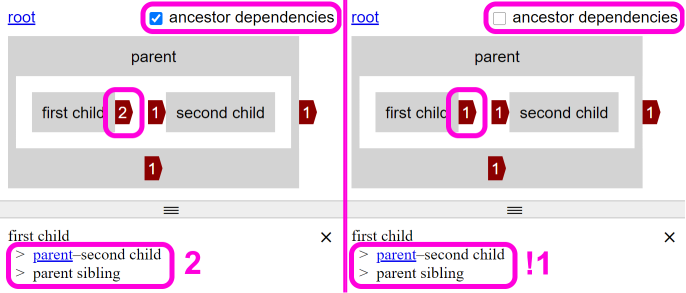
Unfortunately, I've taken a short break from working on the new analyzer. My suspicions in recent posts about issue #155 being incomplete turned out to be more significant than I thought. Although the counts appear to be behaving correctly, I'd completely forgotten to implement the changes for the dependency list (see post image). I've created issue #164 to add this missing behavior as a top priority bug. Its likely to be very confusing, especially to new users, the opposite of the original enhancement's intent.
multi-language analyzer design
2020-09-02
As mentioned in my previous post I've started work on a new analyzer that has its level of detail limited to module/file/namespace, but will support multiple languages.
As this analyzer will support multiple languages it needs to work across different development environments. To make it easy to use, the runtime its based on would need to be included with the tool. Its possible to bundle the runtimes of many languages with software; however, there is a lot of variation in the size of the runtimes.
The Rust language compiles to native, doesn't have a garbage collector and so has a relatively small runtime. It has support for the major operating systems, memory safety and includes some functional programming features.
At the moment I'm getting familiar with the language by writing the command line interface. I hope to move onto analysis soon, most likely first by dogfooding my own Rust code and then building up some tests.
how to support analysis for many languages
2020-08-26
Issue #155, that has been mentioned in the last few posts, is complete and hopefully makes the dependencies in stacks of child items less confusing. I have a feeling it could probably be improved, both in the way its described and some potential complimentary enhancements.
A variation on the recent theme of increasing the likelihood that people will try out Eunice, I would like to make some form of analysis available to most developers. I think the most interesting and helpful way of understanding what Eunice is about is to run it on code people are already familiar with. One barrier to this is that developers use many different languages.
Currently Eunice has full support for JavaScript and C#. JavaScript analysis builds quite a lot onto a syntactic model (from Babel), whereas C# analysis does less as it uses a semantic model (from Roslyn). My plan is to add module/file/namespace analysis for all the popular languages, before adding comprehensive analysis of individual languages.
I've re-ordered the issue backlog to represent this. The order isn't just based on popularity of the languages, but that I'm going to try implementing/dogfooding it in Rust and how quickly I think each language will take. I've also mixed in a quick JavaScript enhancement to break things up.
progress report on making Eunice easier for new users
2020-08-20
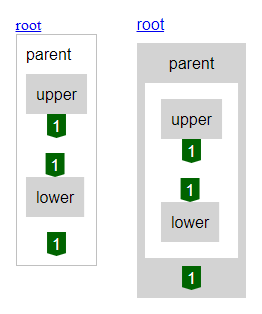
Two of the issues I posted about on 16th are complete (#150 and #154) . I haven't started on the third more nuanced one (#155) as a user created a new issue that would definitely make it easier for people trying to understand what Eunice is visualizing.
This new issue (#156) has been completed, a before and after is shown in this posts image. I'm used to seeing Eunice visualizations and without feedback I might never have realized this was a problem.
latest fixes & enhancements targeted at new users
2020-08-16
As I'm looking to encourage more people to try out Eunice, I thought I'd look at some fixes and enhancements that would make this easier.
There's a couple of issues related to selecting dependencies to be listed (#150 and #154) that shouldn't take long to sort out. The first will remove links that will raise an error and the second adds links that would work but weren't available.
The other issue (#155), might be a bit more nuanced, relates to outer dependency counts (the ones outside the items box). The current behavior works well for software with unidirectional dependencies, but not on software were Eunice is most needed and likely to be the situation of people first using Eunice. Outer dependency counts currently include the stack being viewed, but also all the ancestor stacks, that won't be displayed. This current behavior means users focused on improving a single stack will be distracted by counts that can't be improved by modifying that single stack.
All three issues will be available for both analyzers (C# and JavaScript).
first C# open source project analysed by Eunice
2020-08-13
Now that Eunice's C# analyzer is working, I thought I'd try it out on one of the most ubiquitous open source .NET packages, Newtonsoft Json.NET.
As you might have noticed from the screenshot Eunice isn't able to infer stack levels for a lot of the classes and namespaces. It has them in quite a long interdependent level. I've counted and there's almost the same amount in the lowest level of uni-directional, dependency-less items.